

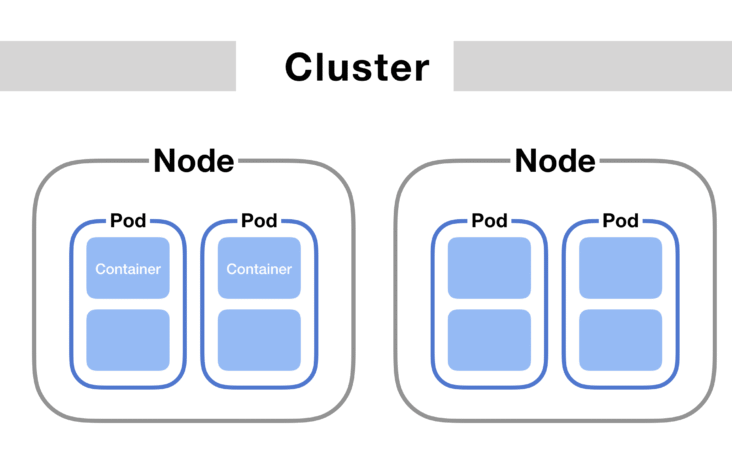
Do you know how does Kubernetes Pod Schedules ?
We all run pod and talk about it but do we really know the components and stages involved in pod’s scheduling. Let’s see briefly the stages involved in below diagram.
The three major components involved are as follows:
– API Server
– Scheduler
– Kubelet
If you run any command such as “kubectl apply -f abc.yml” the below sequence of events happens to create a Pod.
Sequence :
1. Kubernetes client (kubectl) sent a request to the API server requesting creation of a Pod defined in the abc.yml file.
2. Since the scheduler is watching the API server for new events, it detected that there is an unassigned Pod.
3. The scheduler decided which node to assign the Pod to and sent that information to the API server.
4. Kubelet is also watching the API server. It detected that the Pod was assigned to the node it is running on.
5. Kubelet sent a request to Docker requesting the creation of the containers that form the Pod. In our case, the Pod defines a single container based on the mongo image.
Finally, Kubelet sent a request to the API server notifying it that the Pod was created successfully.

Detailed Sequence of Pod Scheduling
- Request to Create a Pod:
- The process begins when a Kubernetes client, typically
kubectl, sends a request to the API server to create a Pod as defined in a YAML configuration file (e.g.,abc.yml). This YAML file contains all the specifications needed for the Pod, such as the container image, resource limits, environment variables, and more.
- The process begins when a Kubernetes client, typically
- Scheduler Watches for Unassigned Pods:
- The Kubernetes scheduler is continuously watching the API server for new Pods that have been created but are not yet assigned to a node. These unassigned Pods are placed in a queue where the scheduler can pick them up for processing.
- Pod Assignment to a Node:
- Once the scheduler picks up an unassigned Pod, it analyzes the resource requirements and other constraints of the Pod. The scheduler considers various factors such as the current load on each node, the available resources, and any affinity/anti-affinity rules specified for the Pod. Based on this analysis, the scheduler selects the most appropriate node for the Pod and communicates this decision back to the API server.
- Kubelet Watches for Pod Assignments:
- Kubelet, running on each node, is also watching the API server for new Pods that have been assigned to its node. When it detects that a Pod has been assigned to the node it is running on, Kubelet takes responsibility for that Pod.
- Container Creation and Pod Startup:
- Kubelet communicates with the container runtime (e.g., Docker) on the node to create the containers as defined in the Pod specification. In the example provided, the Pod contains a single container based on the MongoDB image. Kubelet ensures that this container is started with the correct configuration and that it is running smoothly.
- Notification of Pod Creation:
- After successfully creating the containers and starting the Pod, Kubelet sends a notification back to the API server to inform it that the Pod has been successfully created and is now running. The API server then updates the status of the Pod accordingly.
Additional Considerations in Pod Scheduling
While the basic process of Pod scheduling is straightforward, several additional factors can influence how Pods are scheduled and managed in a Kubernetes cluster:
- Resource Requests and Limits:
- When defining a Pod, it’s essential to specify resource requests and limits for CPU and memory. The resource request is the amount of resources the Pod is guaranteed to receive, while the limit is the maximum amount the Pod can use. Properly setting these values helps the scheduler make more informed decisions and prevents resource contention on nodes.
- Node Affinity and Anti-Affinity:
- Kubernetes allows you to specify rules that influence which nodes a Pod can or cannot be scheduled on. Node affinity rules let you specify that a Pod should be scheduled on nodes with specific labels (e.g., nodes with SSD storage). Anti-affinity rules, on the other hand, prevent Pods from being scheduled on certain nodes or in close proximity to each other, which can be useful for high availability scenarios.
- Taints and Tolerations:
- Taints and tolerations are another way to control how Pods are scheduled. A taint applied to a node prevents Pods that do not have a corresponding toleration from being scheduled on that node. This feature is particularly useful for dedicating nodes to specific workloads, such as batch processing or sensitive workloads that require isolation.
- Pod Disruption Budgets (PDBs):
- PDBs allow you to specify the minimum number or percentage of Pods that must remain available during voluntary disruptions (e.g., during node maintenance). This ensures that your application remains highly available even when certain Pods are being rescheduled or upgraded.
- Horizontal Pod Autoscaling (HPA):
- HPA automatically scales the number of Pods in a deployment or replica set based on observed CPU utilization (or other metrics). This is an essential feature for handling variable workloads efficiently, ensuring that your application can handle spikes in demand without manual intervention.
- Service Discovery and Load Balancing:
- Once a Pod is running, Kubernetes provides service discovery and load balancing capabilities to ensure that traffic is evenly distributed among the available Pods. Services in Kubernetes use labels to match with Pods, and they create an endpoint that can be accessed by other services or users, abstracting the complexity of Pod IP management.
- Network Policies:
- Kubernetes supports network policies that control the communication between Pods and services. By defining network policies, you can implement fine-grained security controls, specifying which Pods can communicate with each other or with external services. This is crucial for securing your applications in a multi-tenant environment.
Kubernetes Pod scheduling is a complex but essential process that ensures your applications run efficiently and reliably within a cluster. By understanding the roles of the API server, scheduler, and Kubelet, and by following best practices for resource management, security, and high availability, you can optimize your Kubernetes deployments for both performance and resilience. As you continue to work with Kubernetes, these insights will help you better manage your workloads and harness the full power of this orchestration platform.