

AWS S3 Vector Search End-to-End Guide
Why Vector Databases Were Created
The rise of AI and machine learning has fundamentally changed how we process and understand data. Traditional databases excel at storing structured data like names, numbers, and categories, but they struggle with the complexity of modern AI applications that need to understand:
- Semantic Similarity: Understanding that “car” and “automobile” mean the same thing
- Contextual Relationships: Knowing that “Apple” the company is different from “apple” the fruit
- Multimodal Data: Connecting images, text, audio, and video based on meaning rather than exact matches
- High-Dimensional Data: Processing data with hundreds or thousands of features simultaneously
The AI Data Challenge
Modern AI systems convert unstructured data (text, images, audio) into vector embeddings – numerical representations that capture semantic meaning. For example:
- The sentence “I love pizza” might become a 768-dimensional vector: [0.2, -0.1, 0.8, …]
- A similar sentence “Pizza is delicious” would have a vector that’s mathematically close in vector space
- Traditional databases can’t efficiently find these “nearby” vectors among billions of records
Mathematical Foundation
Vector databases solve the Approximate Nearest Neighbor (ANN) problem:
- Input: A query vector q and a dataset of n vectors
- Goal: Find the k vectors most similar to q
- Challenge: Exact search is O(n×d) complexity – too slow for real-time applications
- Solution: Use algorithms like HNSW, LSH, or IVF to achieve sub-linear search time
What is a Vector Database?
A vector database is a specialized database designed to store, index, and query high-dimensional vector embeddings efficiently. Unlike traditional databases that store discrete values, vector databases store continuous numerical representations of data that capture semantic meaning and relationships.
Core Components
- Vector Storage: Optimized storage for high-dimensional arrays (typically 128-4096 dimensions)
- Vector Index: Specialized data structures (HNSW, IVF, LSH) for fast similarity search
- Similarity Metrics: Distance functions (cosine, euclidean, dot product) to measure vector similarity
- Metadata Integration: Ability to combine vector search with traditional filtering
- Approximate Search: Trading perfect accuracy for speed using probabilistic algorithms
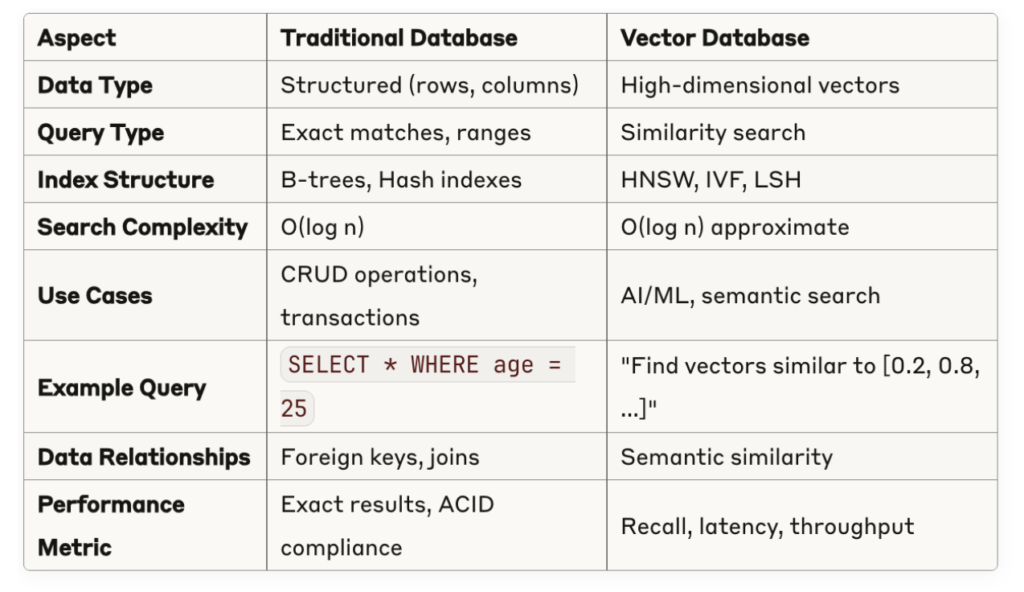
Traditional Database vs Vector Database
Example: Understanding Vector Similarity
# Traditional database query
SELECT title, content FROM articles
WHERE category = 'technology' AND publish_date > '2024-01-01'
# Vector database query (conceptual)
SELECT title, content, similarity_score
FROM articles
WHERE vector_similarity(embedding, query_vector) > 0.8
ORDER BY similarity_score DESC
LIMIT 10When to Use Vector Databases
Perfect for:
- Semantic search and recommendation systems
- RAG (Retrieval-Augmented Generation) applications
- Content discovery and personalization
- Duplicate detection and data deduplication
- Multimodal search (image + text)
- Anomaly detection in high-dimensional data
Not ideal for:
- Traditional CRUD operations
- Financial transactions requiring ACID compliance
- Simple filtering and aggregation queries
- Applications requiring exact matches only
Overview
Amazon S3 Vectors integrates with OpenSearch to provide flexible vector storage and search capabilities, offering up to 90% cost reduction compared to conventional approaches while seamlessly integrating with Amazon Bedrock Knowledge Bases, SageMaker, and OpenSearch for AI applications.
What’s New and Important
Amazon S3 Vectors is a new cloud object store that provides native support for storing and querying vectors at massive scale, offering up to 90% cost reduction compared to conventional approaches while seamlessly integrating with Amazon Bedrock Knowledge Bases, SageMaker, and OpenSearch for AI applications.
Amazon OpenSearch Serverless now supports half (0.5) OpenSearch Compute Units (OCUs) for indexing and search workloads, cutting the entry cost in half.
Architecture Options
Option 1: S3 Vectors + OpenSearch Serverless (Recommended)
- S3 Vectors: Store vectors cost-effectively
- OpenSearch Serverless: Query and search capabilities
- Best for: Large-scale vector storage with cost optimization
Option 2: OpenSearch Serverless Only
- OpenSearch Serverless: Both storage and search
- Best for: Smaller datasets, faster queries, simpler setup
Prerequisites:
# Install AWS CLI
aws --version
# Configure AWS credentials
aws configure
# Install required tools
pip install boto3 opensearch-py numpyPart 1: Setting Up S3 Vectors
1.1 Create S3 Vectors Bucket
# Create S3 bucket with vector configuration
aws s3api create-bucket \
--bucket my-vector-bucket-2024 \
--region us-east-1 \
--create-bucket-configuration LocationConstraint=us-east-1
# Enable versioning (recommended)
aws s3api put-bucket-versioning \
--bucket my-vector-bucket-2024 \
--versioning-configuration Status=Enabled
# Create vector configuration
aws s3api put-bucket-vector-configuration \
--bucket my-vector-bucket-2024 \
--vector-configuration '{
"VectorIndex": {
"Status": "Enabled",
"VectorDimensions": 768,
"VectorDataType": "float32",
"DistanceMetric": "cosine"
}
}'1.2 Upload Vector Data
| # upload_vectors.py import boto3 import numpy as np import json def upload_vectors_to_s3(): s3_client = boto3.client(‘s3’) bucket_name = ‘my-vector-bucket-2024’ # Sample vector data (768-dimensional vectors) vectors = [ { “id”: “doc_1”, “vector”: np.random.rand(768).tolist(), “metadata”: { “title”: “Document 1”, “category”: “technology”, “content”: “AI and machine learning concepts” } }, { “id”: “doc_2”, “vector”: np.random.rand(768).tolist(), “metadata”: { “title”: “Document 2”, “category”: “science”, “content”: “Physics and quantum mechanics” } } |
Part 2: Setting Up OpenSearch Serverless
2.1 Create OpenSearch Serverless Collection
| # Create security policy aws opensearchserverless create-security-policy \ –name vector-search-policy \ –type encryption \ –policy ‘{ “Rules”: [ { “ResourceType”: “collection”, “Resource”: [“collection/vector-search-*”] } ], “AWSOwnedKey”: true }’ # Create network policy aws opensearchserverless create-security-policy \ –name vector-search-network-policy \ –type network \ –policy ‘[ { “Rules”: [ { “ResourceType”: “collection”, “Resource”: [“collection/vector-search-*”] }, { “ResourceType”: “dashboard”, “Resource”: [“collection/vector-search-*”] } ], “AllowFromPublic”: true } ]’ # Create access policy aws opensearchserverless create-access-policy \ –name vector-search-access-policy \ –type data \ –policy ‘[ { “Rules”: [ { “ResourceType”: “collection”, “Resource”: [“collection/vector-search-*”], “Permission”: [“aoss:*”] }, { “ResourceType”: “index”, “Resource”: [“index/vector-search-*/*”], “Permission”: [“aoss:*”] } ], “Principal”: [“arn:aws:iam::YOUR_ACCOUNT_ID:root”] } ]' |
2.2 Create Vector Index
| # create_index.py from opensearchpy import OpenSearch, RequestsHttpConnection from aws_requests_auth.aws_auth import AWSRequestsAuth import boto3 def create_vector_index(): # Get credentials credentials = boto3.Session().get_credentials() awsauth = AWSRequestsAuth(credentials, ‘us-east-1’, ‘aoss’) # OpenSearch client client = OpenSearch( hosts=[{‘host’: ‘your-collection-endpoint.us-east-1.aoss.amazonaws.com’, ‘port’: 443}], http_auth=awsauth, use_ssl=True, verify_certs=True, connection_class=RequestsHttpConnection ) # Create index with vector mapping index_name = “vector-search-index” index_body = { “settings”: { “index”: { “knn”: True, “knn.algo_param.ef_search”: 100 } }, “mappings”: { “properties”: { “vector”: { “type”: “knn_vector”, “dimension”: 768, “method”: { “name”: “hnsw”, “space_type”: “cosinesimil”, “engine”: “lucene”, “parameters”: { “ef_construction”: 128, “m”: 24 } } }, “metadata”: { “properties”: { “title”: {“type”: “text”}, “category”: {“type”: “keyword”}, “content”: {“type”: “text”} } } } } } response = client.indices.create(index_name, body=index_body) print(f”Index created: {response}”) if __name__ == “__main__”: create_vector_index() |
Part 3: Integrating S3 Vectors with OpenSearch
3.1 Set Up S3-OpenSearch Integration
# Create integration between S3 Vectors and OpenSearch Serverless |
3.2 Import Vectors from S3
# import_vectors.py |
Part 4: Querying and Search
4.1 Vector Similarity Search
# search_vectors.py |
4.2 Hybrid Search (Vector + Text)
# hybrid_search.py |
Part 5: Use Cases and Examples
5.1 Document Similarity Search
# Use case: Find similar documents
def find_similar_documents(document_embedding):
results = search_similar_vectors(document_embedding, k=10)
return [r for r in results if r[‘score’] > 0.8]
5.2 Recommendation System
| # Use case: Product recommendations def get_product_recommendations(user_embedding, category_filter=None): search_body = { “size”: 20, “query”: { “bool”: { “must”: [ { “knn”: { “vector”: { “vector”: user_embedding, “k”: 20 } } } ] } } } if category_filter: search_body[“query”][“bool”][“filter”] = [ {“term”: {“metadata.category”: category_filter}} ] # Execute search and return recommendations |
5.3 RAG (Retrieval-Augmented Generation)
| # Use case: RAG for chatbots def retrieve_context_for_rag(question_embedding, top_k=5): relevant_docs = search_similar_vectors(question_embedding, k=top_k) |
Part 6: Monitoring and Optimization
6.1 CloudWatch Metrics
# Monitor OpenSearch Serverless metricsaws cloudwatch get-metric-statistics \ |
6.2 Performance Optimization
# Optimize vector indexing performance |
Challenges and Solutions
Challenge 1: Cold Start Performance
Problem: Initial queries may be slower Solution:
# Implement warming queries search_similar_vectors(dummy_vector, k=1) |
Challenge 2: Vector Dimensionality
Problem: High-dimensional vectors consume more memory Solution:
- Use dimensionality reduction (PCA, UMAP)
- Consider binary vectors for cost savings
- Optimize embedding models
Challenge 3: Data Consistency
Problem: S3 and OpenSearch sync issues Solution:
# Implement eventual consistency checks |
Challenge 4: Cost Management
Problem: Unexpected costs from scaling Solution:
# Implement cost monitoring |
Best Practices
- Index Design:
- Start with fewer dimensions if possible
- Use appropriate distance metrics (cosine for normalized vectors)
- Set optimal HNSW parameters based on your use case
- Cost Optimization:
- Use S3 Vectors for large-scale storage
- Monitor OCU utilization
- Implement efficient batching for indexing
- Performance:
- Use hybrid search for better relevance
- Implement query result caching
- Monitor query latency and adjust accordingly
- Security:
- Use IAM policies for fine-grained access control
- Enable encryption at rest and in transit
- Regularly audit access patterns
Conclusion
AWS S3 Vectors with OpenSearch Serverless provides a cost-effective, scalable solution for vector search, offering up to 90% cost reduction and sub-second query response times. This architecture is ideal for AI applications requiring large-scale vector storage and search capabilities.
The combination offers the best of both worlds: cost-effective storage in S3 Vectors and powerful search capabilities through OpenSearch Serverless, making it suitable for everything from recommendation systems to RAG applications.