
Understanding AWS EC2 Instance Classes: Demystifying M and R Instances
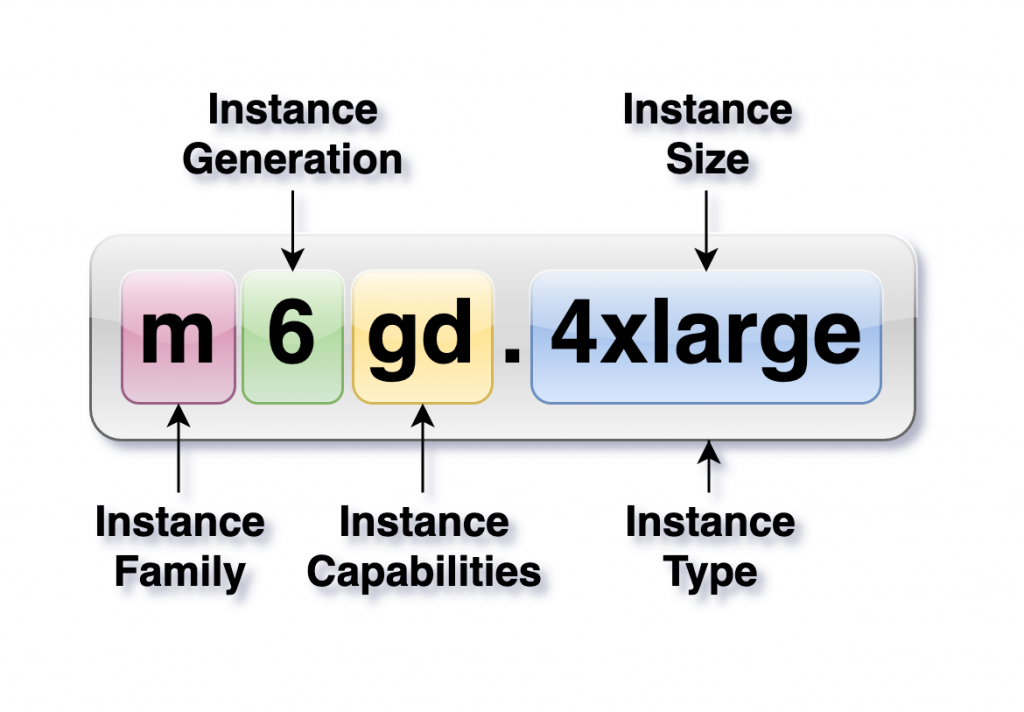
When it comes to AWS EC2 instances, many developers, engineers, and interviewees often struggle to clearly explain the difference between instance classes like M and R. These instances are essential in optimizing resource allocation and improving performance in the cloud. However, misconceptions around what these classes stand for and their use cases can lead to confusion. In this detailed guide, we’ll dive into the key differences between instance classes and types, focusing on M and R instances, to help build a clearer understanding — whether you’re preparing for an AWS interview or just seeking to enhance your AWS knowledge. What Are EC2 Instance Classes? Before we get into M and R instances specifically, let’s first understand the concept of instance classes. An EC2 instance class refers to a family or group of instances designed to meet specific resource needs for particular workloads. AWS organizes its instances into classes based on performance characteristics, which enables users to select the best instance for their requirements. Each class is tailored to optimize specific resources like memory, computing power, storage, or networking performance. Here are some common EC2 instance classes: Instance Types vs. Instance Classes An important distinction to make when discussing EC2 instances is the difference between instance types and instance classes. Knowing both the class and the type is critical when choosing the right instance for your workload, as the specific type within a class may be better suited for your needs. Breaking Down M Instances: General Purpose Workhorse M instances are AWS’s General Purpose instances, and they are designed to provide a balance between CPU, memory, and network performance. These instances are ideal for workloads that require a relatively even distribution of resources and don’t lean heavily on one particular resource like memory or CPU. Use Cases for M Instances M instances are commonly used for: R Instances: Memory-Optimized Performance R instances, on the other hand, are part of AWS’s Memory-Optimized instance class. These instances are designed to handle workloads that require a significant amount of memory. If your application deals with large datasets that need to be processed in-memory or requires high-speed access to memory, R instances are your best bet. Use Cases for R Instances R instances are well-suited for memory-intensive applications like: Key Differences Between M and R Instances While M and R instances may appear similar at first glance, their main difference lies in the optimization of resources: The choice between M and R instances should be based on your workload requirements. If your application needs balanced performance, M instances are the way to go. But if your application is memory-intensive and requires large amounts of memory for processing data, R instances are the better choice. Why This Matters for Interviews and Real-World Scenarios Asking about M and R instances in interviews helps test a candidate’s ability to understand AWS resource allocation at a deeper level. It’s not just about remembering that “M is for memory” (which is actually incorrect!) — it’s about understanding how to choose the right instance class for specific workloads. For interviews, knowing the difference between instance classes shows a deeper understanding of AWS’s capabilities. Employers want to see that you’re not just memorizing terms but understanding how to apply AWS resources efficiently in real-world scenarios. For practical use, understanding instance classes and types helps optimize your application’s performance and cost-efficiency in the cloud. Selecting the wrong instance class could lead to unnecessary expenses or suboptimal performance. Here are some examples of commonly used AWS EC2 instance classes and their specific use cases: These examples illustrate how different classes address specific resource needs (CPU, memory, storage), allowing you to tailor your AWS environment to the demands of your workload. Do you know what is the class for t2.micro instance and why it is used ? The T2.micro instance belongs to the T class, specifically the T2 family of Burstable Performance instances. These instances are designed to provide a baseline level of CPU performance with the ability to burst when needed. The T2.micro instance is ideal for low-traffic applications, small databases, or development and testing environments. It offers 1 vCPU and 1 GB of RAM, and it’s commonly used in AWS’s free tier for light workloads that don’t require consistent, high CPU usage.
The Shift-Left Strategy: Catching Security Issues Early

In the fast-paced world of software development, finding and fixing security vulnerabilities as early as possible is crucial. That’s where the Shift-Left Strategy comes into play. It’s all about moving security testing and code reviews to the beginning of the development process—before the code even gets close to production. By shifting security left in your DevOps pipeline, you catch issues early, reduce risks, and save time in the long run. Here are some simple tips to help you adopt this strategy !! 1. Start with Secure Code Reviews Before any code is merged into your project, it should go through a security review. This helps to spot vulnerabilities like insecure coding practices or risky dependencies from the get-go. Tip:Integrate security reviews as part of your regular code reviews. Tools like SonarQube or Codacy can help you automate code analysis and catch security flaws early. 2. Include Security in CI/CD Pipelines Your Continuous Integration (CI) and Continuous Delivery (CD) pipelines are ideal places to implement automated security checks. This way, every time new code is committed, it gets tested for security issues. Tip:Use tools like Snyk, Checkmarx, or Aqua Security to scan for vulnerabilities in your code, dependencies, and container images during each build and deployment. 3. Shift Security Testing Left Security testing often happens after development is done, but with the Shift-Left approach, it happens much earlier. By incorporating security tests into unit and integration tests, teams can find vulnerabilities during the development process itself. Tip:Set up static and dynamic security tests as part of your testing suite. Static Application Security Testing (SAST) tools can analyze your code for flaws, while Dynamic Application Security Testing (DAST) tools simulate attacks on running applications. 4. Collaborate Early and Often Security isn’t just the responsibility of the security team—it’s everyone’s job. Developers, testers, and security teams should collaborate right from the design phase to ensure security is baked into every step of the project. Tip:Encourage cross-team collaboration with regular meetings and shared security practices. This will help bridge gaps and ensure security is part of the entire development lifecycle. 5. Automate Security Policies To catch security issues early and consistently, use automated tools to enforce security policies. This ensures that any code that doesn’t meet security standards is flagged immediately, long before it can cause problems in production. Tip:Integrate security policies using tools like Open Policy Agent (OPA) or Kubernetes Admission Controllers to enforce compliance across your pipelines and infrastructure. 6. Educate Your Team Adopting a Shift-Left strategy means that everyone on the development team needs to be security-conscious. Training developers on common security threats, vulnerabilities, and best practices can go a long way in preventing security issues. Tip:Provide regular training on secure coding practices and how to use security testing tools effectively. This empowers developers to think about security as they code. Conclusion The Shift-Left Strategy empowers teams to address security issues before they become costly problems. By integrating security checks, tests, and reviews early in the DevOps process, organizations can build more secure applications from the start, reduce risks, and save time.
Choosing the Right Gateway: Navigating API Gateway vs Ingress Controller vs NGINX in Kubernetes
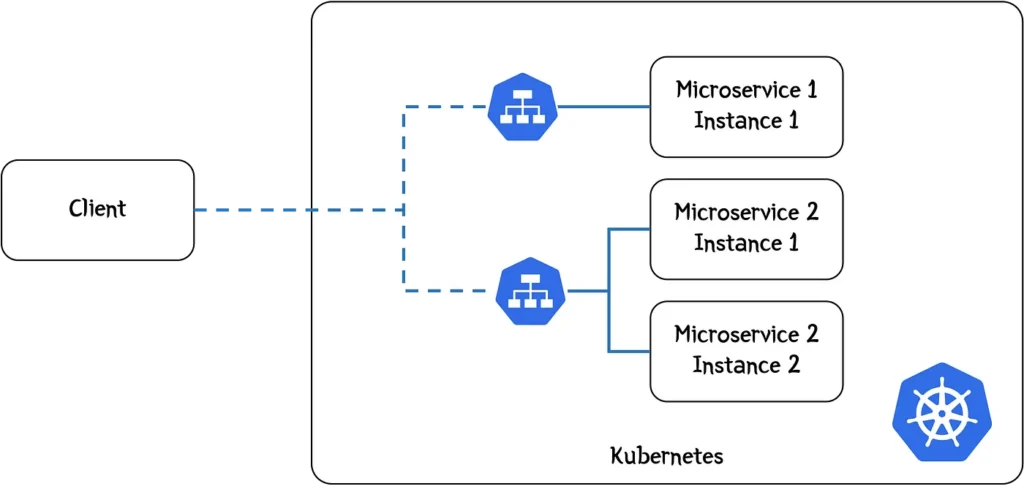
When building microservices-based applications, it can be challenging to determine which technology—API Gateway, NGINX, or an Ingress Controller—is best for connecting services. These tools play distinct roles in managing traffic, but each has its own set of strengths depending on the use case. Understanding the Key Components: Choosing the Right Solution: Real-World Use Cases: #Pseudo Code for API Gateway routingroutes: – path: /order-history services: – user-service – order-service 2. Internal Application in KubernetesFor a simple internal application where different teams use distinct services, an Ingress Controller can be set up to manage HTTP/S routing, exposing internal applications securely within the cluster. # Pseudo Ingress RuleapiVersion: networking.k8s.io/v1kind: Ingressmetadata: name: internal-appspec: rules: – host: app.internal.example.com http: paths: – path: /team1 backend: service: name: team1-service port: number: 80 3. Hybrid SolutionA hybrid scenario might use both an API Gateway for external API requests and NGINX as a load balancer within the Kubernetes cluster. This setup is common for public-facing applications where internal service-to-service communication requires more granular control. Choosing between an API Gateway, Ingress Controller, or NGINX boils down to your application needs. API Gateways are best for complex routing and security, while Ingress Controllers are ideal for HTTP routing in Kubernetes, and NGINX offers flexibility for custom traffic management. Advanced Use Case: Advanced Use Case: Microservices-based Financial Platform with API Gateway, NGINX, and Service Mesh Imagine a financial platform where you handle multiple services like user authentication, payments, and transactions. In this scenario: Architecture: Pseudocode Example: This setup can include defining an API Gateway for external APIs, and using an Ingress Controller for internal routing. For inter-service communication, a Service Mesh will enforce security and provide monitoring. Code Link: https://github.com/sacdev214/apigatwaycode.git This architecture ensures that: Scenario-Based Questions and Answers: 1. Scenario: You are working with a simple Kubernetes cluster running internal services with no external traffic. Which component would be best to route traffic between these services? 2. Scenario: A public-facing e-commerce website needs to handle thousands of requests per minute, with several microservices handling user profiles, orders, and payments. Which component should you use for managing these requests efficiently? 3. Scenario: You need to enforce strict rate limiting, traffic throttling, and security policies on external APIs exposed by your Kubernetes services. Which tool should you consider? 4. Scenario: Your application is deployed on Kubernetes and has simple HTTP services that need exposure to the internet. What is the most Kubernetes-native solution? 5. Scenario: You are building a microservices architecture where each service communicates with others via HTTP, and you need to ensure inter-service communication is secure and well-monitored. Which solution would be best?
The Future of DevOps and Cloud 2024

As technology evolves, DevOps practices are constantly improving to meet the demands of modern software development. This article looks at the key trends and advancements in DevOps, from emerging tools to cultural changes. By understanding where DevOps is headed, businesses can better prepare for the challenges and opportunities ahead. Key Takeways: Source: Spacelift DevOps Trends: The Future of DevOps In the next 10 years, DevOps will change dramatically. Containers will become a core part of application development and operations. Serverless functions and microservices will make applications more flexible, though managing these technologies could become more complex. To adapt, DevOps workflows and tools will need to evolve. As container-native and cloud applications grow, better tools will emerge, including web-based development environments. Developers may no longer need to install tools locally, as these may come through Software as a Service (SaaS) solutions, possibly restricted to enterprise cloud systems. As cloud-native tools improve, developers may no longer need to write code locally or install tools on their computers. Cloud-based, web-integrated development environments (IDEs) may become the norm, though some of these innovations could be limited to enterprise cloud systems. The future of DevOps is promising, with technologies like AI, machine learning, and containerization leading the way. As companies strive to develop software faster and more efficiently, these trends will play a key role in shaping the future of DevOps.
Mastering System Design Interviews: Key Questions and Tips for Success
When preparing for a System Design Interview (SDI), it’s easy to feel overwhelmed by the breadth and depth of knowledge required. Whether you’re a seasoned developer or new to the field, understanding how to approach these questions is crucial for success. In this blog, we’ll explore some common system design questions, from easy to hard, along with tips to help you navigate the interview process with confidence. Easy System Design Interview Questions 1. Design an API Rate Limiter An API rate limiter is a crucial component for platforms like Firebase or GitHub, which serve thousands of requests per second. Your task is to design a system that limits the number of requests a user can make to an API within a specified time frame, preventing abuse and ensuring fair usage. Key Considerations: 2. Design a Pub/Sub System A pub/sub system, such as Kafka, allows for asynchronous communication between different parts of a system. The challenge is to design a system where publishers send messages to topics and subscribers receive those messages. Key Considerations: 3. Design a URL-Shortening Service Designing a service like TinyURL or bit.ly involves creating a system that takes long URLs and generates shorter, unique versions. Key Considerations: Medium System Design Interview Questions 4. Design a Chat Service Services like Facebook Messenger or WhatsApp are examples of complex chat systems. Your goal is to design a system that supports real-time messaging between users. Key Considerations: 5. Design a Mass Social Media Service Social media platforms like Facebook or Instagram serve millions of users daily. The challenge is to design a system that supports user profiles, posts, likes, comments, and a newsfeed. Key Considerations: 6. Design a Proximity Service A service like Yelp or a feature like “Nearby Friends” on social media platforms relies on determining users’ locations and providing relevant results. Key Considerations: Hard System Design Interview Questions 7. Design a Social Media Newsfeed Service The newsfeed is a central feature of many social media platforms. Your task is to design a system that curates and displays content for users based on their interactions. Key Considerations: 8. Design a Collaborative Editing Service Services like Google Docs allow multiple users to edit documents simultaneously. The challenge is to design a system that supports real-time collaboration without conflicts. Key Considerations: 9. Design Google Maps Designing a service like Google Maps involves creating a system that handles complex geographic data and provides routing and location services. Key Considerations: Tips for Tackling System Design Interview Questions 1. Start with Requirements: Begin by listing the key features your system needs to support. Identify potential challenges like traffic load, data storage needs, and user concurrency. This process will help you plan and also allows the interviewer to clarify any misunderstandings. 2. Narrate Trade-offs: Every design decision comes with pros and cons. Whether it’s choosing a database, a caching strategy, or an algorithm, explain the trade-offs involved. This shows your ability to think critically and make informed decisions. 3. Ask Clarifying Questions: Most SDI questions are deliberately broad, leaving room for interpretation. Asking clarifying questions not only helps you understand the problem better but also demonstrates your thoroughness and problem-solving approach. 4. Know Your Architectures: Modern systems often rely on microservices architecture for flexibility and scalability. Be prepared to discuss how you’d use microservices and how they can interact with legacy systems if applicable. 5. Discuss Emerging Technologies: Conclude your discussion by considering how emerging technologies like machine learning, AI, or blockchain could enhance the system. This shows you’re forward-thinking and prepared to build systems that can adapt to future needs. Related Questions and Answers Q1: What are the different strategies for implementing an API rate limiter? A1: There are several strategies for implementing an API rate limiter, each with its own use cases: Q2: How do you ensure message durability in a Pub/Sub system like Kafka? A2: Message durability in a Pub/Sub system can be ensured through several mechanisms: Q3: What are the key challenges in designing a URL-shortening service, and how can they be addressed? A3: The main challenges in designing a URL-shortening service include: Q4: In a chat service like WhatsApp, how do you manage message ordering and delivery guarantees? A4: Managing message ordering and delivery guarantees in a chat service involves: Q5: How would you handle data consistency in a distributed system, such as a social media platform? A5: Handling data consistency in a distributed system can be challenging due to the CAP theorem, which states that you can only have two of the following three: Consistency, Availability, and Partition Tolerance. Strategies include: Q6: What are some common challenges in designing a video streaming service like Netflix, and how can they be mitigated? A6: Designing a video streaming service involves several challenges: Q7: How would you design a search engine-related service like Typeahead, and what are the key considerations? A7: Designing a Typeahead service, where suggestions are shown as the user types, involves: Q8: What are the trade-offs between using microservices and a monolithic architecture when designing a system like Uber or Lyft? A8: The trade-offs between microservices and monolithic architectures include: #TechInterviews #SoftwareEngineering #Microservices #Scalability #TechTips #ProfessionalDevelopment #skillupwithsachin
Observability in Linux Performance: A Visual Guide
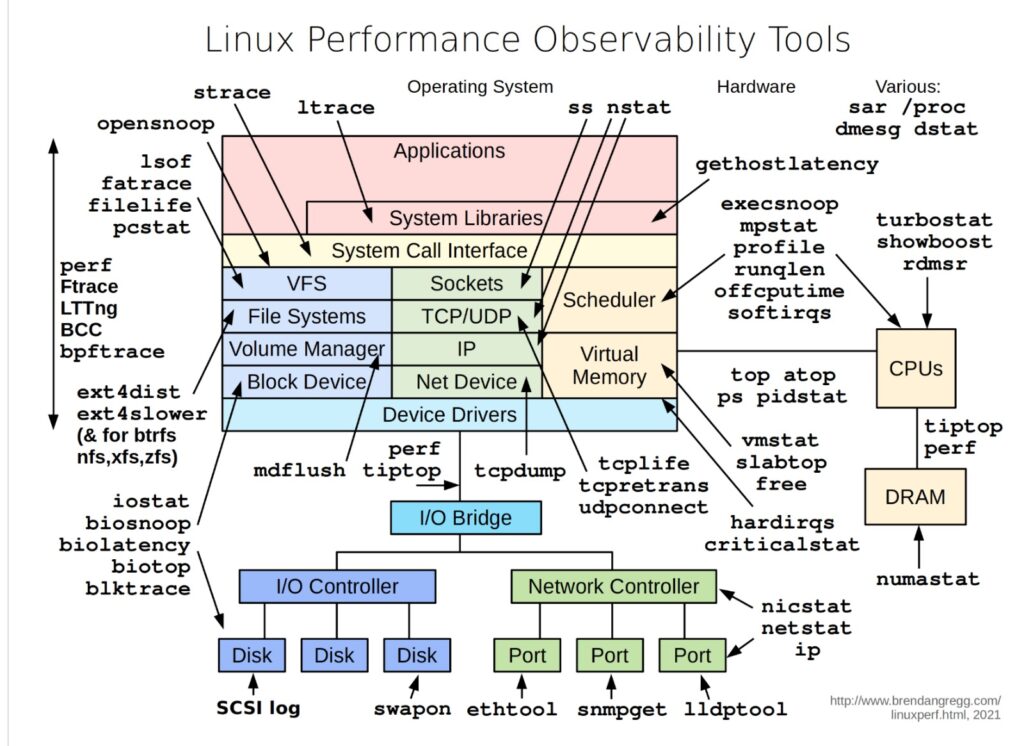
In today’s world, where the performance of systems is critical to business success, understanding and monitoring Linux performance is more important than ever. The visual guide provided above is a powerful tool for system administrators, DevOps engineers, and SREs to gain insights into the various components of a Linux system, from hardware to applications, and how they interact. Understanding the Layers of Linux Performance The diagram breaks down Linux performance observability into multiple layers, each representing different parts of the system: Example Use Cases Conclusion This visual guide is not just a map but a toolkit that offers a structured way to approach Linux performance issues. Each tool has its place, and by understanding where and how to use them, you can effectively diagnose and resolve performance bottlenecks, ensuring your systems run smoothly and efficiently. For anyone serious about maintaining high-performance Linux environments, mastering these tools and understanding their use cases is not optional — it’s essential.
Unlocking Developer Productivity with DevPod: The Ultimate Open-Source Dev Environment Solution

As developers, we’re always on the lookout for tools that simplify our workflows, enhance productivity, and provide flexibility in our development environments. Enter DevPod—an open-source marvel that promises to revolutionize the way we manage our development containers. Whether you’re working locally or leveraging the cloud, DevPod brings the magic of dev containers to any infrastructure, empowering you to write and run code seamlessly. What is DevPod? DevPod is an open-source tool designed to launch development containers on any available infrastructure, be it local Docker daemons, Kubernetes, AWS, GCP, Azure, or several other cloud providers. This flexibility means you’re no longer tied to managed services like Codespaces or Gitpod to experience the full benefits of dev containers. Key Features of DevPod DevPod Architecture How DevPod Works DevPod uses a provider model similar to Terraform’s. Providers determine how and where your workspaces run, making it possible to develop on virtual machines, Docker containers, Kubernetes clusters, and more. Here’s a brief overview of the provisioning process: Types of Providers Providers in DevPod are categorized into four types: Advantages Over Hosted Services Compared to hosted services like GitHub Codespaces, JetBrains Spaces, or Google Cloud Workstations, DevPod stands out with several advantages: The Kitchen Analogy: Understanding DevPod To understand DevPod better, let’s use a kitchen analogy. Imagine a professional kitchen where each chef has everything they need to prepare their dishes to perfection: Potential Challenges While DevPods offer numerous benefits, they also come with their own set of challenges: Real-Life Example: Developing a Web Application Imagine a team developing a web application. Each developer has their own DevPod, pre-configured with necessary tools and dependencies. Developer A works on the frontend, Developer B on the backend, and Developer C on database integration. They work in isolated environments, ensuring their changes don’t affect others until they’re ready to merge. Getting Started with DevPod To learn more about DevPod, visit devpod.sh. For installation instructions, head over to GitHub. If you have questions, join the DevPod channel on Slack. Conclusion DevPod is poised to change the way we manage development environments, offering flexibility, control, and efficiency. By using DevPod, development teams can work more efficiently, maintain consistency, and scale effortlessly—just like a well-organized kitchen where each chef has everything they need to prepare their dishes to perfection. Join the DevPod revolution today and experience the future of development environments! #devops #devpods #containers #devcontainers
Common Mistakes we do while Configuring Prometheus and AlertManager on EKS Cluster
Prometheus and AlertManager are one of the most in-demand tools used for Monitoring & Alerting in the industry currently. They are one of the efficient tools to be used for monitoring your EKS cluster along with the custom metrics you are pushing.However, with this configuration we tend to make lot of mistakes which makes our deployment difficult. I have tried to collate all the common mistakes we do while configuring and deploying Prometheus and AlertManager which will help us to deploy the Prometheus stack in smoother way. Configuring Prometheus and Alertmanager on an Amazon EKS cluster can be a bit complex due to the various components involved and potential pitfalls. Here are some common mistakes that people might make during this process: Prometheus needs to be able to discover and scrape the metrics endpoints of your applications. Incorrectly configuring service discovery, such as using incorrect labels or selector configurations, can result in Prometheus not being able to collect metrics. Fix: Ensure correct labels and selectors for Kubernetes services and Pods. 2. Improper Pod Annotations or Labels: In Kubernetes, pods need to have appropriate annotations or labels to be discovered by Prometheus. If these annotations or labels are missing or incorrect, Prometheus won’t be able to locate the pods for scraping. Fix: Add the correct Prometheus Annotations or Labels to your pods. 3. Insufficient Resources: Prometheus can be resource-intensive, especially as the number of monitored targets increases. Failing to allocate sufficient CPU and memory resources to your Prometheus pods can lead to performance issues and potential crashes. Fix: Allocate sufficient resources to Prometheus Pods 4. Misconfigured Retention and Storage: Prometheus stores time-series data, and its retention and storage settings need to be properly configured to match your use case. Failing to do so can result in excessive storage usage or data loss. Fix : Configure retention and storage settings in Prometheus configuration.
Useful Tips & Tricks for Building Resume & Getting Job

Check out this informative video on DevOps by me !! In the video, I have talked about tips and tricks for DevOps, as well as interview preparation and resume building. Additionally, they discuss various DevOps projects to practice. Don’t miss out on this valuable resource! Tips and Tricks for Mastering DevOps Building a Strong DevOps Resume Your resume is your first impression. Make sure it reflects your skills and experience effectively. By following the tips and tricks outlined here, preparing thoroughly for interviews, and building a resume that showcases your expertise, you’ll be well on your way to a successful career in DevOps. Remember, the key to success in DevOps lies in fostering a collaborative culture, embracing automation, and always striving for continuous improvement. Happy learning! #skillupwithsachin #resume #learning #tipsandtricks #resumebuilding #interviewtricks
Do you know how does Kubernetes Pod Schedules ?
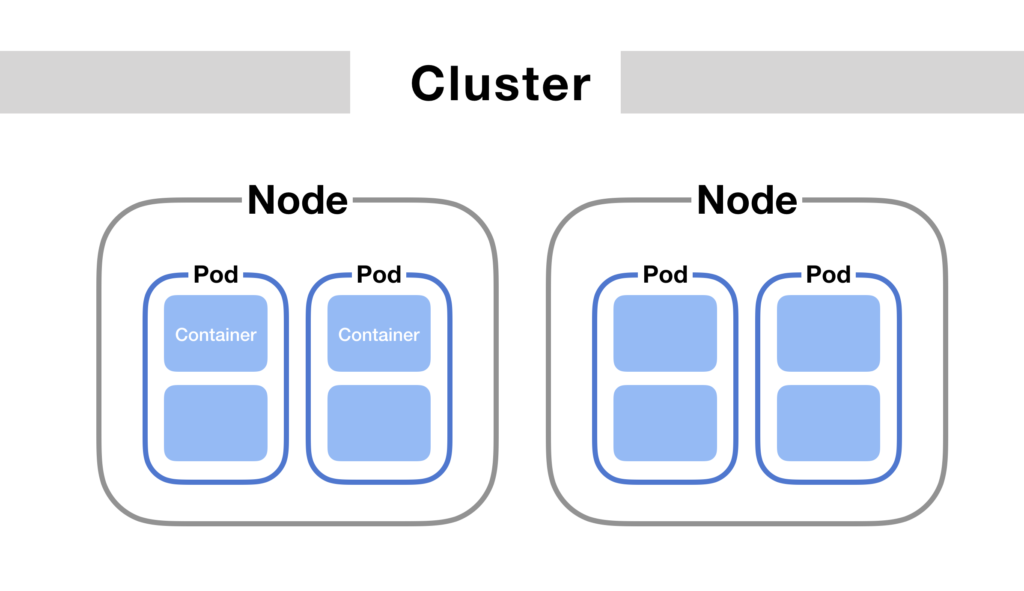
We all run pod and talk about it but do we really know the components and stages involved in pod’s scheduling. Let’s see briefly the stages involved in below diagram. The three major components involved are as follows:– API Server– Scheduler– Kubelet If you run any command such as “kubectl apply -f abc.yml” the below sequence of events happens to create a Pod. Sequence :1. Kubernetes client (kubectl) sent a request to the API server requesting creation of a Pod defined in the abc.yml file.2. Since the scheduler is watching the API server for new events, it detected that there is an unassigned Pod.3. The scheduler decided which node to assign the Pod to and sent that information to the API server.4. Kubelet is also watching the API server. It detected that the Pod was assigned to the node it is running on.5. Kubelet sent a request to Docker requesting the creation of the containers that form the Pod. In our case, the Pod defines a single container based on the mongo image. Finally, Kubelet sent a request to the API server notifying it that the Pod was created successfully. Detailed Sequence of Pod Scheduling Additional Considerations in Pod Scheduling While the basic process of Pod scheduling is straightforward, several additional factors can influence how Pods are scheduled and managed in a Kubernetes cluster: Kubernetes Pod scheduling is a complex but essential process that ensures your applications run efficiently and reliably within a cluster. By understanding the roles of the API server, scheduler, and Kubelet, and by following best practices for resource management, security, and high availability, you can optimize your Kubernetes deployments for both performance and resilience. As you continue to work with Kubernetes, these insights will help you better manage your workloads and harness the full power of this orchestration platform.