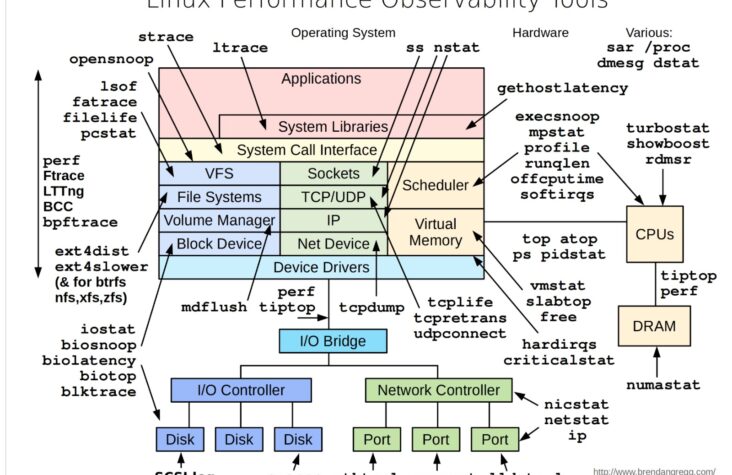
Observability in Linux Performance: A Visual Guide
In today’s world, where the performance of systems is critical to business success, understanding and monitoring Linux performance is more important than ever. The visual guide provided above is a powerful tool for system administrators, …
