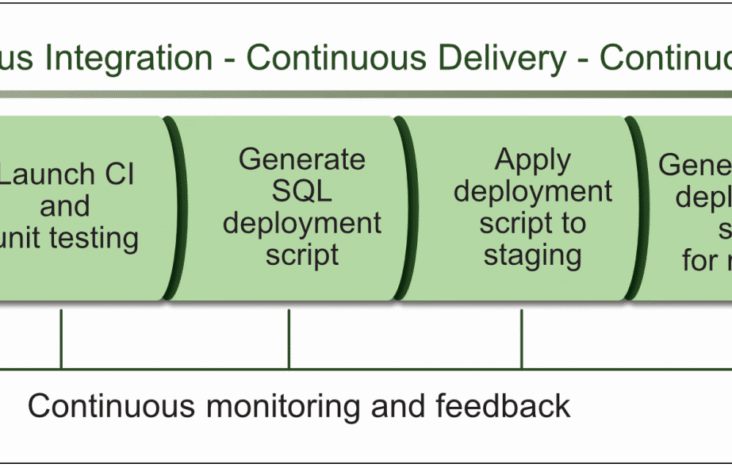
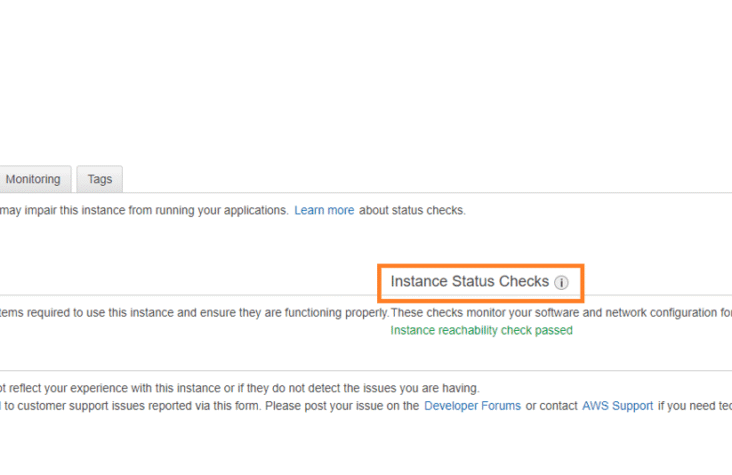
AWS EC2 Status Checks: An Overview
AWS EC2 status checks are automated health checks that monitor the functionality and operability of your EC2 instances. They provide crucial insights into the state of the underlying hardware, network connectivity, and the operating system …