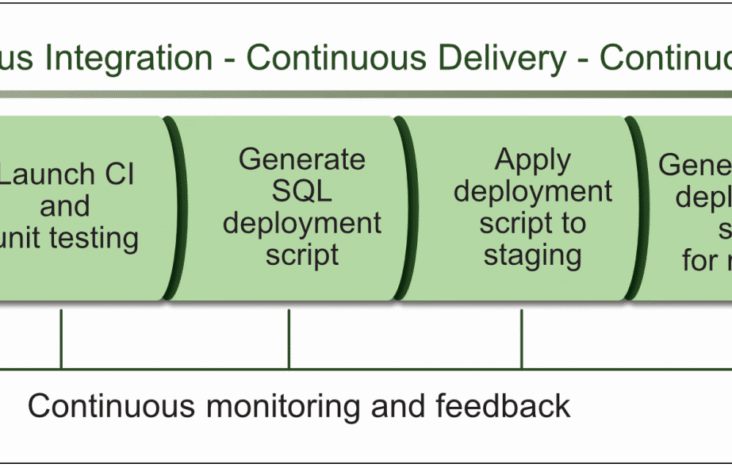
Managing Containers Without Kubernetes: A Glimpse Into Challenges and Solutions
Imagine a world without Kubernetes. A world where containers, those lightweight, portable units of software, existed, but their management was a daunting task. Let’s delve into the challenges that developers and operations teams faced before …