
Understanding bash vs dash — What Every DevOps Engineer Should Know
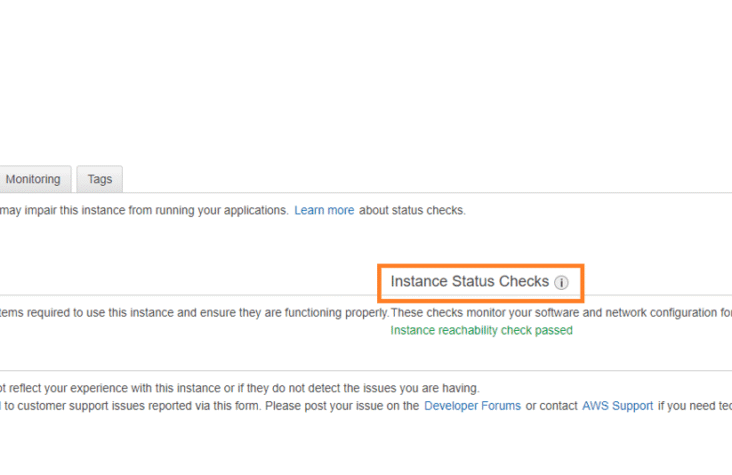
When writing shell scripts or running automation tools like Ansible, you’ll often see /bin/sh, /bin/bash, or even errors like: This confusion stems from differences between bash and dash — two popular Unix shells. Let’s explore …